
書籍!BookLiveから電子書籍のランキング情報をスクレイピング

BookLiveとは?
「ブックライブ」は、凸版印刷グループの総合電子書籍ストアです。 2011年よりサービスを開始し、マンガ、書籍、ラノベ、雑誌など、国内最大級の品揃えを誇ります。 読者の利便性を最優先に、いつでも、どこでも簡単に楽しめるサービスを提供しています。
スクレイピングツールの概要
ScrapeStormとは、強い機能を持つ、プログラミングが必要なく、使いやすく人工知能Webスクレイピングツールです。違う基盤のユーザーに二つのスクレイピングモードを提供し、1-Clickで99%のWebスクレイピングを満たします。ScrapeStormにより、大量のWebデータを素早く正確的に取得できます。手動でデータ抽出が直面するさまざまな問題を完全に解決し、情報取得のコストを削減し、作業効率を向上させます。
抽出されたデータは下記のようにご覧ください。

1.タスクを新規作成する
(1)URLをコピーする
今回はランキング一覧ページを例として、スクレイピング方法を紹介します。まず、URLをコピーしてください。

(2)スマートモードタスクを新規作成する
ScrapeStormのホムページ画面にスマートモードタスクを新規作成します。また、持っているタスクをインポートすることもできます。
詳細には下記のチュートリアルをご参照ください。
スマートモードタスクの新規作成方法
2.タスクを構成する
(1)ページボタン
ソフトウェアは自動的に次のページボタンを識別できます。今回は「スクレイピング」に識別しますが、手動で「50位~100位」ボタンを選んでください。また、もし識別失敗になったら、手動でページボタンをやり直すか、Xpathを編集することもできます。詳細は下記のチュートリアルをご参照ください。
ページをめぐる方法

(2)詳細ページに行く
書籍の詳細情報を取得するために、詳細ページに行く機能を利用してください。詳細ページのリンクが違うの時、「フィールドを追加」ボタンを利用して、書名をクリックすると、ソフトウェアは自動的にリンクを抽出します。

(3)フィールドの追加と編集
フィールドの追加には、「フィールドを追加」ボタンをクリックして、画面に抽出する要素を選択、データが自動的に抽出されます。また、必要に応じてフィールド名の変更、削除、結合などの編集もできます。
フィールドの設定の詳細には下記のチュートリアルをご参照ください。
抽出されたフィールドを配置する方法

3.タスクの設定と起動
(1)起動の設定
必要に応じて、スケジュール、アンチブロック、自動エクスポート、画像のダウンロード、スピードブーストを設定できます。今回は画像のダウンロードをチェックしてください。
スクレイピングタスクを配置する方法については、下記のチュートリアルをご参照ください。
スクレイピングタスクを配置する方法

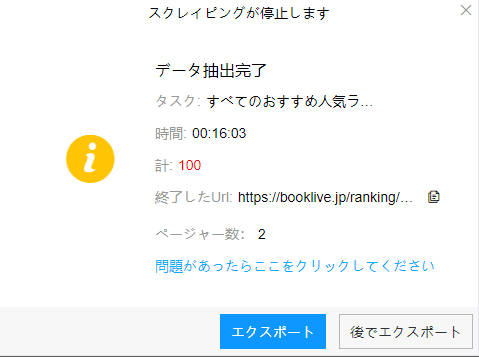
(2)しばらくすると、データがスクレイピングされる。

4.抽出されたデータのエクスポートと表示
(1)エクスポートをクリックして、データをダウンロードする
(2)必要に応じてエクスポートする形式を選択します。
ScrapeStormは、Excel、csv、html、txt、データベース、ローカルなどさまざまなエクスポート方法を提供します。ライトプラン以上のユーザーは、WordPressに直接投稿することもできます。
抽出結果のエクスポート方法の詳細には下記のチュートリアルをご参照ください。
抽出されたデータのエクスポート方法
