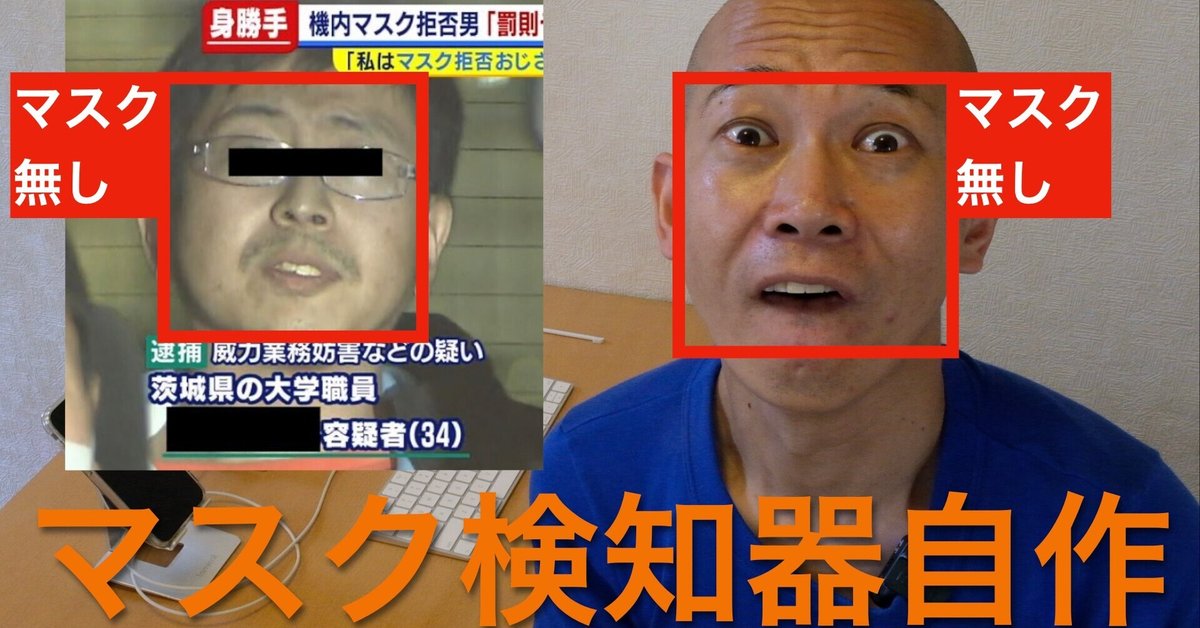
[ラズパイ使って電子工作]マスク検知器を自作してマスク拒否男を撃退してみた

どうも~、IoT探検家のシンクンです。
コロナ禍になってからマスクの着用が必須になってしまいましたね。僕はマスクの着用はあまり好きではないですが、公共機関や飲食店を利用するときにはマスクを着用するように心がけています。
多くの人も同じだと思いますが、中にはマスク着用を拒んで周りに迷惑をかけてしまっている人もいたりしますね。そうです、あの人です。マスク拒否男😊。
AIを使うと顔画像からマスクを着用しているかどうかを判断できるので、今回はそれを利用してマスク検知器、名付けて「マスク拒否男撃退装置」の自作にチャレンジしてみました~🤣。
それでは作り方を見てみましょう。
用意したもの
・ラズパイ本体(Raspberry Pi 4)
・4インチのLCDモニター
・USBカメラ
・ミニスピーカー
・キーボードとマウス
・パソコン
・microSDカード
・HDMIケーブル(microHDMI→HDMI)
・USB-C接続の電源アダプター
全体の流れ
1)ラズパイ(タブレット)にOpenCVをインストール
2)パソコンからラズパイ(タブレット)を遠隔操作するためにVNCを設定
3)GitHubから学習済みのマスク検知モデルをダウンロード
4)マスク検知モデルをカスタマイズ
5) 「マスク拒否男撃退装置 」完成
準備として以下の2点が行われている必要があります。
・ラズパイの初期設定 ➡「[普通科高校卒の週末プログラマー]ラズパイの初期設定をしてみた」を御覧ください
・ラズパイのタブレット化 ➡「[普通科高校卒の週末プログラマー]手のひらサイズのタブレットを自作してみた」を御覧ください
1)ラズパイ(タブレット)にOpenCVをインストール
ここは前回の「OpenCVのインストール」でやったことと全く同じですので、簡単説明になります。
まずはmicroSDカードの中のRaspbianのファイルシステムの拡張をおこない、その後に淡々とOpenCVと依存関係のあるソフトのインストール。そしてPythonの仮想環境を作って、OpenCVをインストールする流れでしたね。

これを画面の小さいタブレットにキーボードを繋いでやってみたら、「LXTerminal」でコマンド打つ時に字が小さくてストレスを感じました。そこでちょっと調べてみたところ、パソコンからラズパイを遠隔操作できる方法が分かったのです。
2)パソコンからラズパイ(タブレット)を遠隔操作するためにVNCを設定
その方法とはVNCです。VNCを設定することでパソコンの画面からタブレットの画面を操作できるようになります。(参考にしたサイト:【ラズベリーパイ入門】PCから遠隔操作する方法(VNC)徹底解説)
VNCとは
Virtual Network Computingの略。ネットワーク上の離れたコンピュータを遠隔操作するためのRFBプロトコルを利用する、リモートデスクトップソフト。VNCはクロスプラットフォームなソフトウェアとして開発されているため、インストールされているマシン同士はOSなどのプラットフォームの種類に依存することなく通信できる。
VNCにはサーバーとクライアントの2種類の役割があるようで、操作される側のラズパイにVNCサーバーを、操作する側のパソコンにVNCクライアントを用意します。


まずはラズパイ側ですが、ラズパイには元からVNCサーバーが組み込まれているので、上の添付写真のように、メニューバーから設定 > Raspberry Piの設定 > インターフェイスと進み、VNCを有効にします。


一方のパソコン側はVNCクライアントソフトのVNC Viewerをダウンロード。ダウンロードできたら起動して、上の入力欄にラズパイのホスト名raspberrypi.localを入力してenter。そうすると、ラズパイにログインするためのUsernameとPasswordが求められるので入力します。(デフォルトではUsernameは pi で、Passwordは raspberryと設定されているようです。

するとパソコンの画面にラズパイ(タブレット)の画面が表示されました!
これで小さな画面でコマンドを打つストレスから開放されました~。
3)GitHubから学習済みのマスク検知モデルをダウンロード
続いて学習済みのマスク検知モデルを準備しましょう。
利用するのはインド人のエンジニアの方が、ディープラーニングを使って学習させたマスク検知モデル「Face-Mask-Detection」で、GithubからダウンロードできMITライセンスで利用できます。
(※ここで言っているモデルの学習とは、AIにマスクを着用している人と着用していない人の区別ができるように教えることです。具体的には、コンピュータにマスクを着用している人と着用していない人の画像を大量に与えて、繰り返し数値計算を行って区別ができるようにします。この学習には処理能力の高いコンピュータが必要で、それはラズパイでは難しいので、今回は既に区別できるように学習済みのモデルを利用させてもらいます。)
MIT ライセンスとは
マサチューセッツ工科大学で作成された代表的な寛容型オープンソースライセンスのひとつ。 MIT ライセンスの規定はシンプルで、ソフトウェアを自由に扱ってよいこと、再頒布時に著作権表示とライセンス表示を含めること、作者や著作権者はいかなる責任も負わないことを定めています。


最初に、上の添付写真のように、GitHubからDownload ZIPでFace-Mask-Detection-masterをダウンロードして、ラズパイにフォルダを配置。
workon cv
pip install tensorflowまた、マスク検知モデル「Face-Mask-Detection」はTensorFlow(テンソルフロー)を使っているので、上のコマンドでラズパイPythonの仮想環境にTensorFlowをインストールします。(参照:pip での TensorFlow のインストール)
TensorFlow(テンソルフロー)とは
Googleが開発しオープンソースで公開している、機械学習に用いるためのソフトウェアライブラリ
続いて、ラズパイに外付けのUSBカメラを取り付けて、リアルタイムに動画で顔画像を取り込めるようにします。
workon cv
cd /home/pi/Desktop/Face-Mask-Detection-master
python detect_faces.py
ここまで出来たら、上のコマンドのように、workon cvコマンドを入れてPythonの仮想環境を立ち上げて、face-detectionフォルダに移動してから、detect_mask_video.pyファイルを実行です。(上のコマンドはデスクトップにface-detectionフォルダがおいてある例です。)


するとラズパイの画面にカメラから取り込まれた動画が表示され、マスクを着用していれば緑色の枠が顔に描かれ、着用していなければ緑色の枠が描かれます。
※エラー解消
python detect_faces.pyを実行したら以下のようなエラーが出るかもしれません。
File "/databricks/python/lib/python3.7/site-packages/tensorflow_core/python/keras/saving/save.py", line 146, in load_model
return hdf5_format.load_model_from_hdf5(filepath, custom_objects, compile)
File "/databricks/python/lib/python3.7/site-packages/tensorflow_core/python/keras/saving/hdf5_format.py", line 166, in load_model_from_hdf5
model_config = json.loads(model_config.decode('utf-8'))
AttributeError: 'str' object has no attribute 'decode'これはTensorFlow(テンソルフロー)で動くニューラルネットワークのライブラリーKeras(ケラス)が、HDF5フォーマットファイルを取り扱うための Python ライブラリーであるh5pyの最新バージョン3.1.0に対応していないのが原因です。(参照はこちらの英語のサイト。)
これを解消するために以下のようにおこない、h5pyのバージョンを2.10.0に変更しました。
pip3 show h5py
cd home/pi/.virtualenvx/cv/lib/python3.7/site-packages
pip uninstall h5py
pip install h5py==2.10.0
pip3 show h5pyでh5pyのバージョンが3.1.0であることとファイルの場所がhome/pi/.virtualenvx/cv/lib/python3.7/site-packagesだと分かるので、そこに移動してインストールをやり直します。
4)マスク検知モデルをカスタマイズ
ここまででラズパイを使ってマスク検知はできるようになりましたが、まだ画面に緑色か赤色の枠が表示されるだけなので、コードを少しカスタマイズして「マスク拒否男撃退装置」に変えていきましょう~😆
まずはマスクを着用している人と着用していない人のどちらかを検知した時に、ラズパイから音声が出るようにしたいです。そのためにpygame(パイゲーム)をインストールします。
pygameとは
ビデオゲームを製作するために設計されたクロスプラットフォームのPythonモジュール集であり、Pythonでコンピュータグラフィクスと音声を扱うためのライブラリを含んでいる。
pip install pygame
sudo apt-get install git curl libsdl2-mixer-2.0-0 libsdl2-image-2.0-0 libsdl2-2.0-01つ目のコマンドでpygameをインストールし、2つ目のコマンドでグラフィックの描画やサウンドの再生などのAPIを提供するマルチメディアライブラリSDL (Simple DirectMedia Layer)をインストール。

次にFace-Mask-Detection-masterフォルダの中に音声ファイルを置きます(alarm.wavファイルが音声ファイルです)。
# USAGE
# python detect_mask_video.py
# import the necessary packages
from tensorflow.keras.applications.mobilenet_v2 import preprocess_input
from tensorflow.keras.preprocessing.image import img_to_array
from tensorflow.keras.models import load_model
from imutils.video import VideoStream
import numpy as np
import argparse
import imutils
import time
import cv2
import os
#カスタマイズ開始
import pygame
from threading import Thread
#カスタマイズ終了
#カスタマイズ開始
def sound_alarm(path):
pygame.init()
pygame.mixer.music.load('alarm.wav')
pygame.mixer.music.play()
time.sleep(2)
pygame.mixer.music.stop()
#カスタマイズ終了
def detect_and_predict_mask(frame, faceNet, maskNet):
# grab the dimensions of the frame and then construct a blob
# from it
(h, w) = frame.shape[:2]
blob = cv2.dnn.blobFromImage(frame, 1.0, (300, 300),
(104.0, 177.0, 123.0))
# pass the blob through the network and obtain the face detections
faceNet.setInput(blob)
detections = faceNet.forward()
# initialize our list of faces, their corresponding locations,
# and the list of predictions from our face mask network
faces = []
locs = []
preds = []
# loop over the detections
for i in range(0, detections.shape[2]):
# extract the confidence (i.e., probability) associated with
# the detection
confidence = detections[0, 0, i, 2]
# filter out weak detections by ensuring the confidence is
# greater than the minimum confidence
if confidence > args["confidence"]:
# compute the (x, y)-coordinates of the bounding box for
# the object
box = detections[0, 0, i, 3:7] * np.array([w, h, w, h])
(startX, startY, endX, endY) = box.astype("int")
# ensure the bounding boxes fall within the dimensions of
# the frame
(startX, startY) = (max(0, startX), max(0, startY))
(endX, endY) = (min(w - 1, endX), min(h - 1, endY))
# extract the face ROI, convert it from BGR to RGB channel
# ordering, resize it to 224x224, and preprocess it
face = frame[startY:endY, startX:endX]
face = cv2.cvtColor(face, cv2.COLOR_BGR2RGB)
face = cv2.resize(face, (224, 224))
face = img_to_array(face)
face = preprocess_input(face)
# add the face and bounding boxes to their respective
# lists
faces.append(face)
locs.append((startX, startY, endX, endY))
# only make a predictions if at least one face was detected
if len(faces) > 0:
# for faster inference we'll make batch predictions on *all*
# faces at the same time rather than one-by-one predictions
# in the above `for` loop
faces = np.array(faces, dtype="float32")
preds = maskNet.predict(faces, batch_size=32)
# return a 2-tuple of the face locations and their corresponding
# locations
return (locs, preds)
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-f", "--face", type=str,
default="face_detector",
help="path to face detector model directory")
ap.add_argument("-m", "--model", type=str,
default="mask_detector.model",
help="path to trained face mask detector model")
ap.add_argument("-c", "--confidence", type=float, default=0.5,
help="minimum probability to filter weak detections")
#カスタマイズ開始
ap.add_argument("-a", "--alarm", type=str, default="alarm.wav", help="path alarm .WAV file")
#カスタマイズ終了
args = vars(ap.parse_args())
#カスタマイズ開始
ALARM_ON =False
#カスタマイズ終了
# load our serialized face detector model from disk
print("[INFO] loading face detector model...")
prototxtPath = os.path.sep.join([args["face"], "deploy.prototxt"])
weightsPath = os.path.sep.join([args["face"],
"res10_300x300_ssd_iter_140000.caffemodel"])
faceNet = cv2.dnn.readNet(prototxtPath, weightsPath)
# load the face mask detector model from disk
print("[INFO] loading face mask detector model...")
maskNet = load_model(args["model"])
# initialize the video stream and allow the camera sensor to warm up
print("[INFO] starting video stream...")
vs = VideoStream(src=0).start()
time.sleep(2.0)
# loop over the frames from the video stream
while True:
# grab the frame from the threaded video stream and resize it
# to have a maximum width of 400 pixels
frame = vs.read()
frame = imutils.resize(frame, width=400)
# detect faces in the frame and determine if they are wearing a
# face mask or not
(locs, preds) = detect_and_predict_mask(frame, faceNet, maskNet)
# loop over the detected face locations and their corresponding
# locations
for (box, pred) in zip(locs, preds):
# unpack the bounding box and predictions
(startX, startY, endX, endY) = box
(mask, withoutMask) = pred
# determine the class label and color we'll use to draw
# the bounding box and text
label = "Mask" if mask > withoutMask else "No Mask"
color = (0, 255, 0) if label == "Mask" else (0, 0, 255)
#カスタマイズ開始
if label == "No Mask" and not ALARM_ON:
ALARM_ON = True
t = Thread(target=sound_alarm, args=(args["alarm"],))
t.deamon = True
t.start()
else:
ALARM_ON = False
#カスタマイズ終了
# include the probability in the label
label = "{}: {:.2f}%".format(label, max(mask, withoutMask) * 100)
# display the label and bounding box rectangle on the output
# frame
cv2.putText(frame, label, (startX, startY - 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.45, color, 2)
cv2.rectangle(frame, (startX, startY), (endX, endY), color, 2)
# show the output frame
cv2.imshow("Frame", frame)
key = cv2.waitKey(1) & 0xFF
# if the `q` key was pressed, break from the loop
if key == ord("q"):
break
# do a bit of cleanup
cv2.destroyAllWindows()
vs.stop()最終的にdetect_faces.pyファイルはこのようにカスタマイズされました。(#カスタマイズ開始と#カスタマイズ終了で囲まれているところが追加したコードになります。)
簡単にコードを説明してみます。
30-89行目付近のdef detect_and_predict_mask(frame, faceNet, maskNet):からのところで、detect_and_predict_mask関数を定義。faceNetという顔認識モデルを使って顔を予測して顔座標を返し、顔が1つ以上認識できた場合はmaskNetというマスク認識モデルを使ってマスクの予測をして確率を返す。
129-176行目付近のwhile True:からのところで、カメラが顔を検知した時のラズパイ画面上の描写を定義。検知した顔上にマスクがなければ、赤色の枠線を表示しアラームを鳴らし、検知した顔上にマスクがあれば、緑色の枠線を表示する。
5) 「マスク拒否男撃退装置 」完成
下の画像に写っているものを使ってマスク拒否男撃退装置を組み立て。カメラに加えて外付けのスピーカーもラズパイに接続し、柱にガムテープで巻きつけました🤣。


組み立て終わったので使ってみます。


画面に赤色の枠が表示されている時には、マスク拒否男を撃退するアラートがなっています💣
写真だと分かりづらいので、ここはYouTube動画で見てもらいたいです~
これで「マスク拒否男撃退装置」が完成です!マスク拒否男にお困りの方は使ってみてくださいね。
振り返り
・VNCを設定することで、パソコンの画面からタブレットの画面を操作できるので便利。
・マスク検知モデルを学習からおこなって作るのは大変なので、学習済みのモデルを使うことで時間とお金を節約。その場合、商用利用もできるMITライセンスで配布されているモデルを選んだほうが良い。
・今回の「マスク拒否男撃退装置」の自作にかかった時間は180分でした。(人が映る丁度よいカメラの高さに調整するのに意外と時間がかかってしまいました~汗)
Youtubeで見る
この記事が気に入ったらサポートをしてみませんか?